diff --git a/docs/zh/sakurallmkagglecolab.md b/docs/zh/sakurallmkagglecolab.md
new file mode 100644
index 00000000..5e59e853
--- /dev/null
+++ b/docs/zh/sakurallmkagglecolab.md
@@ -0,0 +1,85 @@
+## 部署SakuraLLM到Kaggle/Google Colab
+
+### 1. 注册[ngrok](https://ngrok.com/),以将请求转发给llama.cpp服务
+
+注册后,分别获取[NGROK_TOKEN](https://dashboard.ngrok.com/get-started/your-authtoken)和[NGROK_DOMAIN](https://dashboard.ngrok.com/cloud-edge/domains),以供后面使用。
+
+
+ NGROK_TOKEN
+ 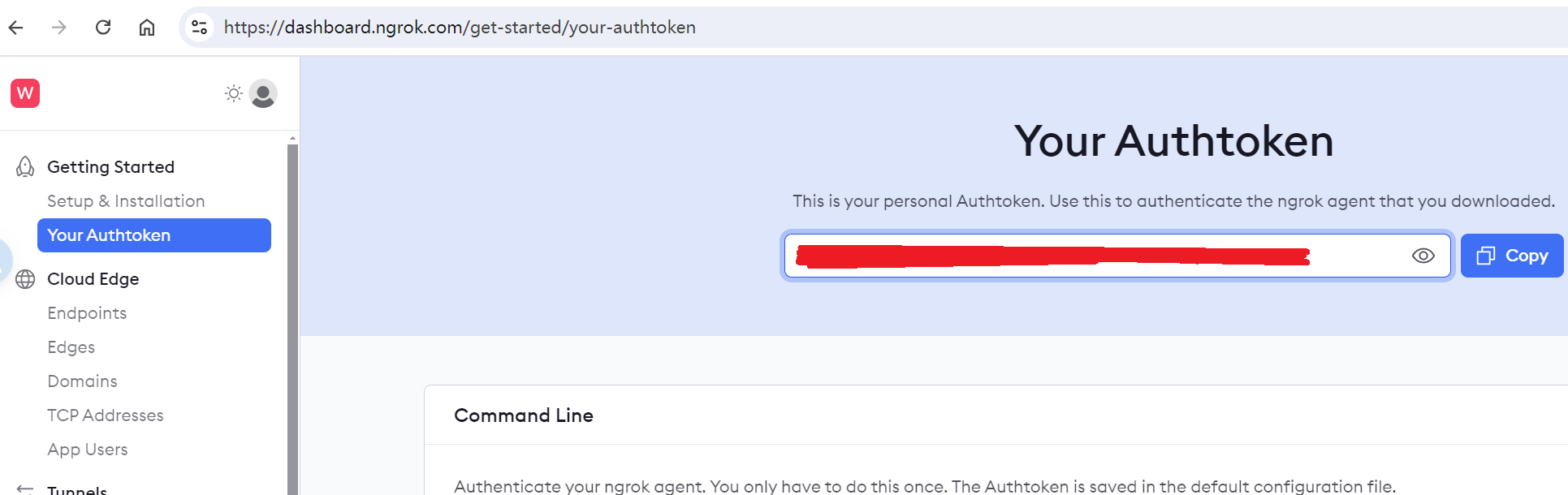 +
+
+
+
+ NGROK_DOMAIN
+ 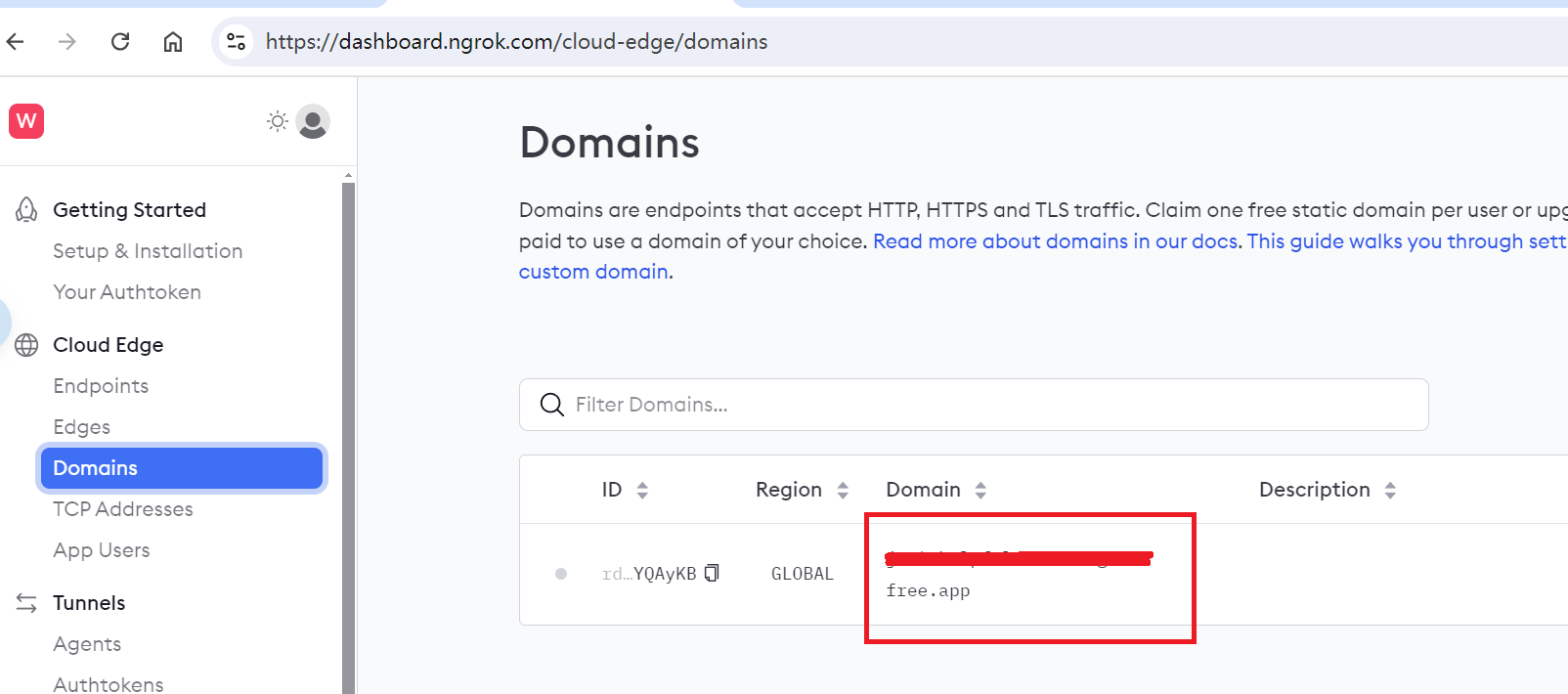 +
+
+
+>之后,在Sakura大模型的设置中,将**API接口地址**填写为`https://`加上**NGROK_DOMAIN**即可,该地址不会发生变化。
+
+
+### 2. 部署到Kaggle/Google Colab
+
+
+
+### **Kaggle**
+
+1. 注册Kaggle,导入ipynb脚本
+
+
+ 2. 选择GPU运行时,打开网络连接。首次使用需要验证手机号
+  +
+ 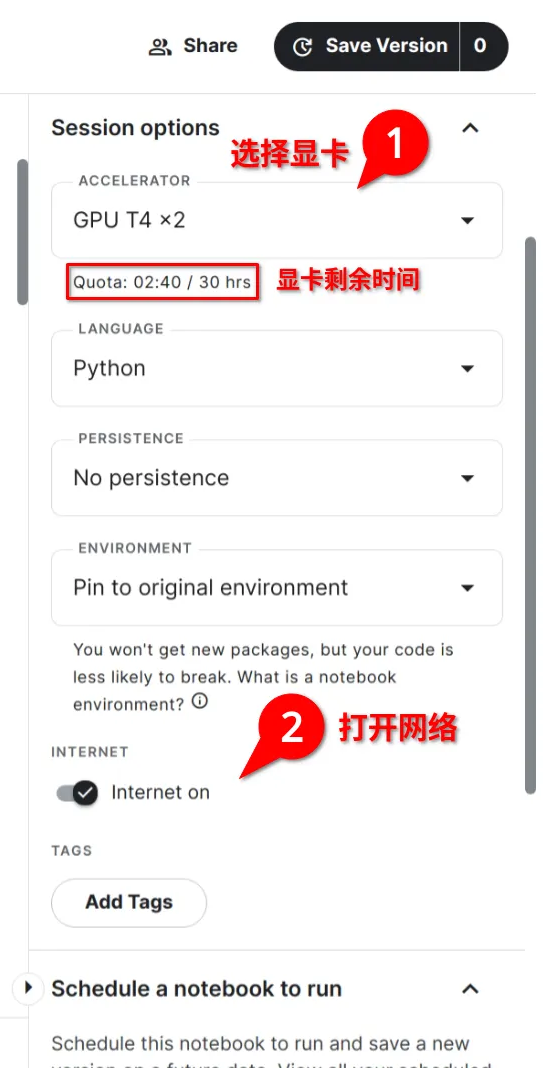 +
+
+
+
+ 3. 设置ngrok密钥和域名,以及使用的模型
+ 将注册的ngrok的NGROK_TOKEN和NGROK_DOMAIN填入脚本中。
+ REPO和MODEL是https://huggingface.co/REPO下的MODEL模型文件名
+  +
+
+
+
+ 4. 运行脚本,稍微等待一分钟左右即可
+ llama.cpp是已经预先编译好的,省去了编译的时间,因此主要是下载模型需要花费一点时间。
+  +
+
+
+### **Google Colab**
+
+
+
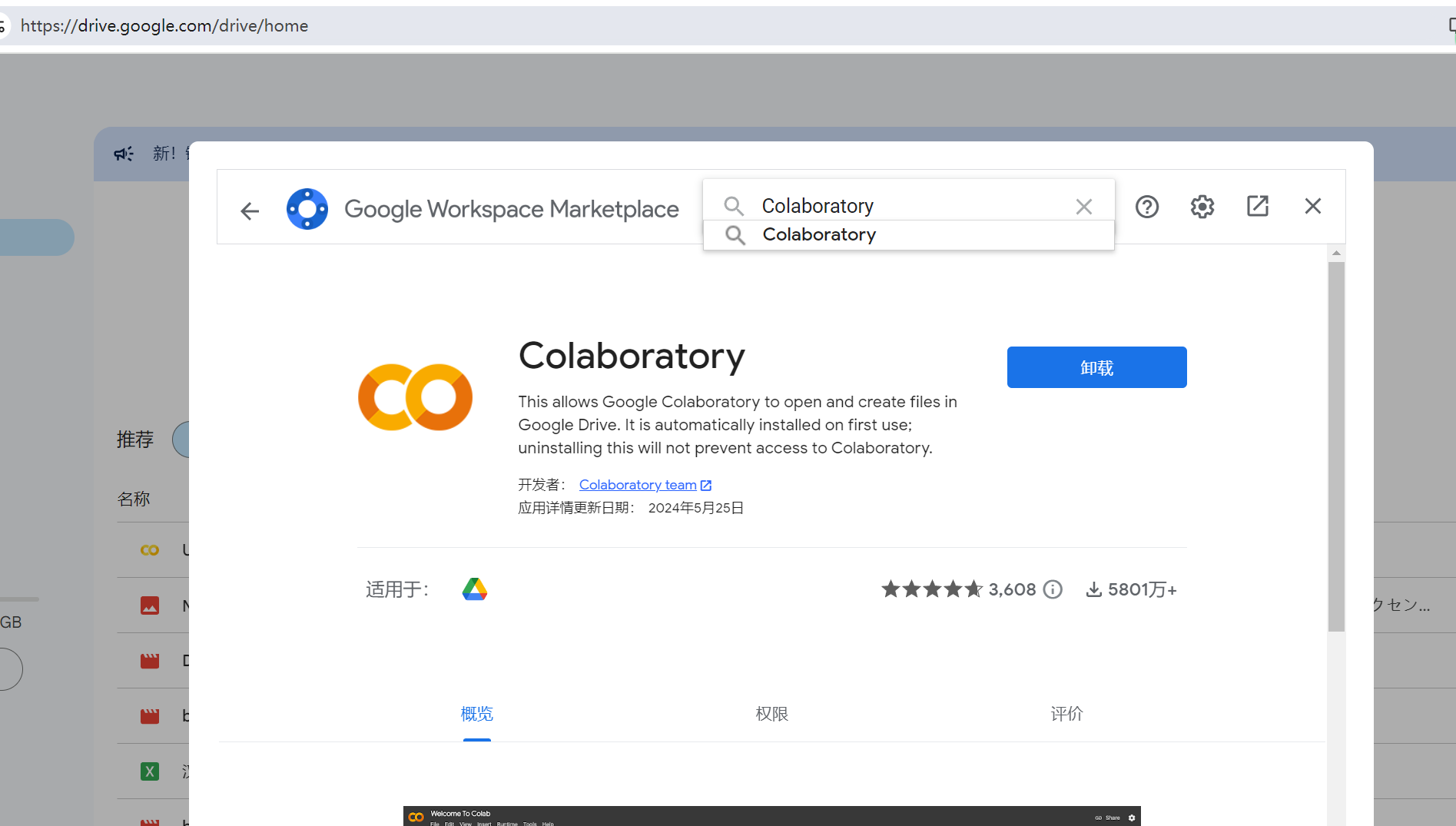
+ 1. 在Google drive中安装Colaboratory应用
+ 点击新建->更多->关联更多应用
+ 在应用市场中搜索Colaboratory安装即可
+ 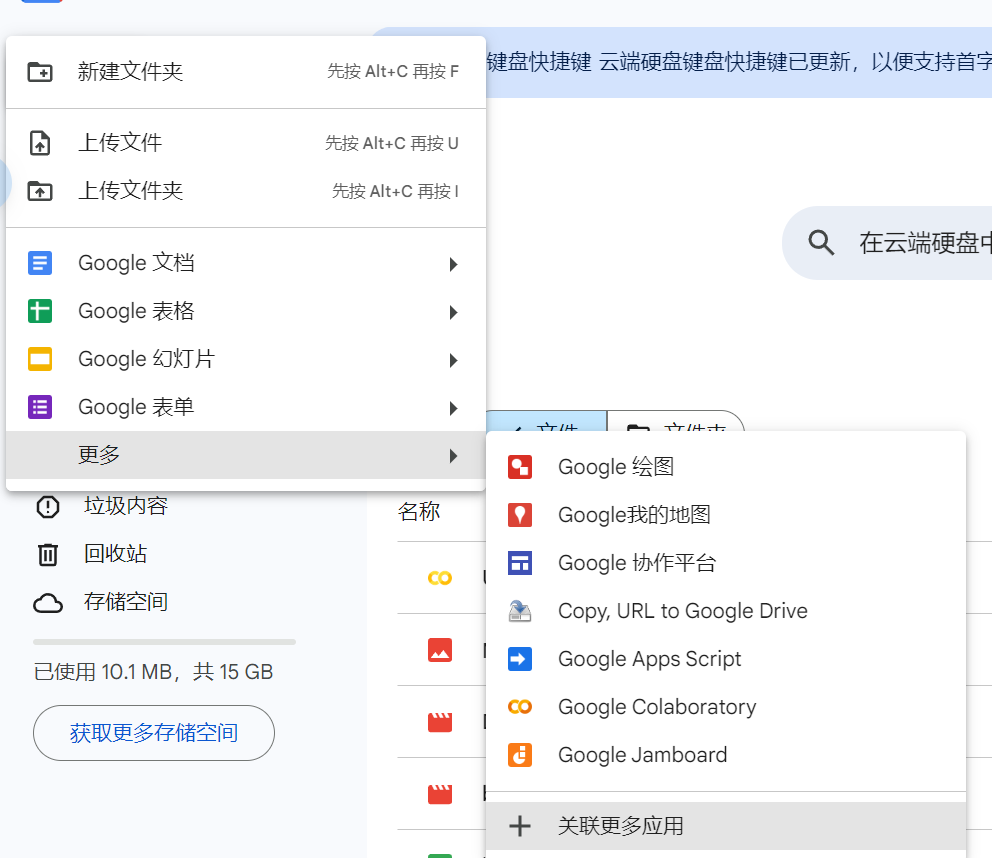 +
+  +
+
+
+
+
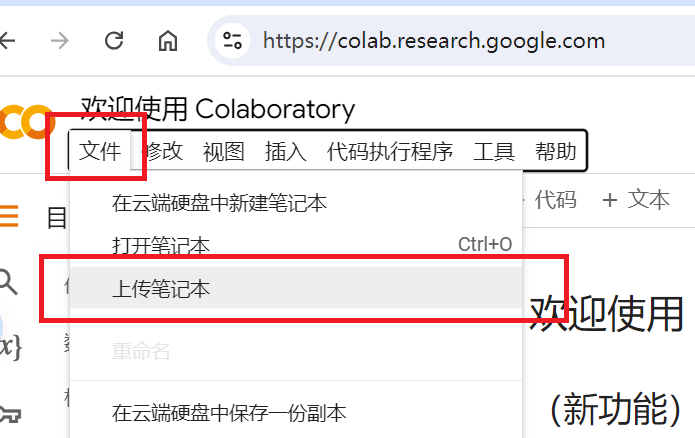
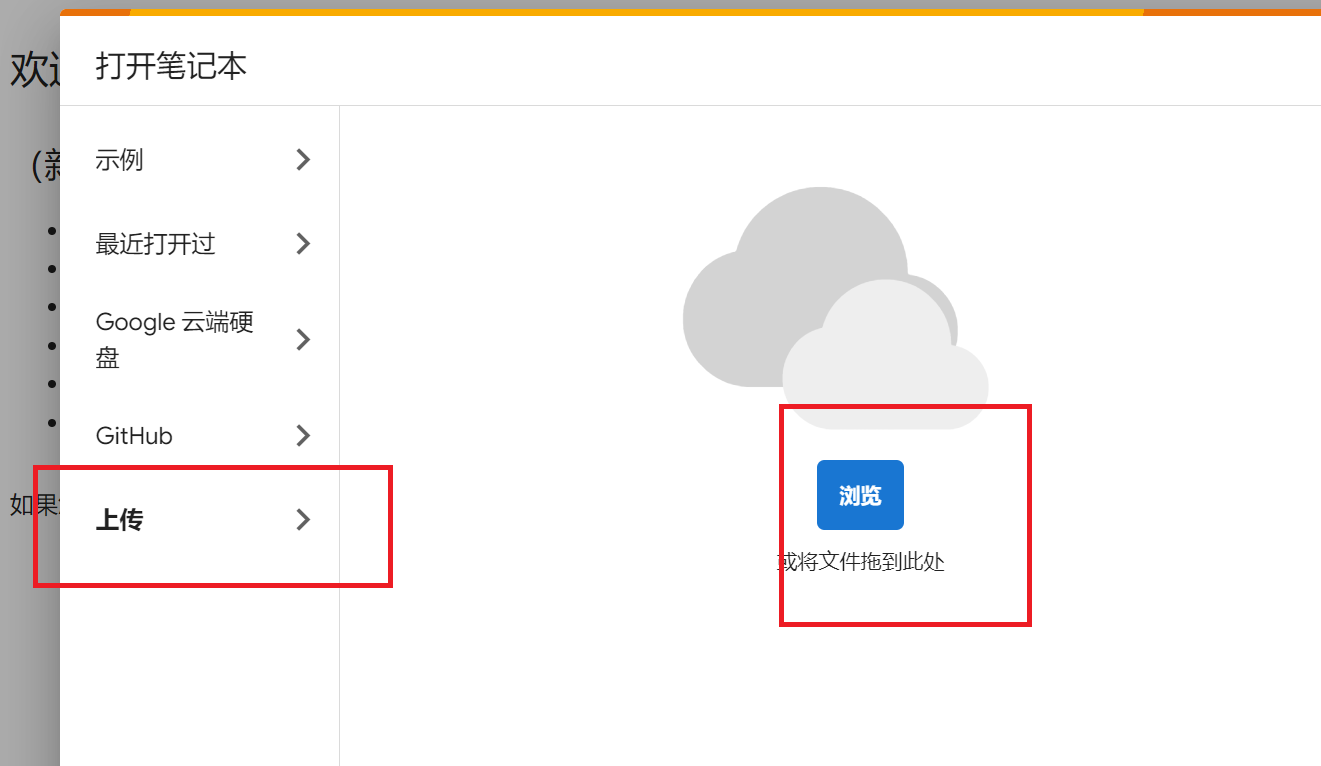
+ 2. 打开Colab,下载ipynb脚本并上传到Colab中。
+  +
+  +
+
+
+
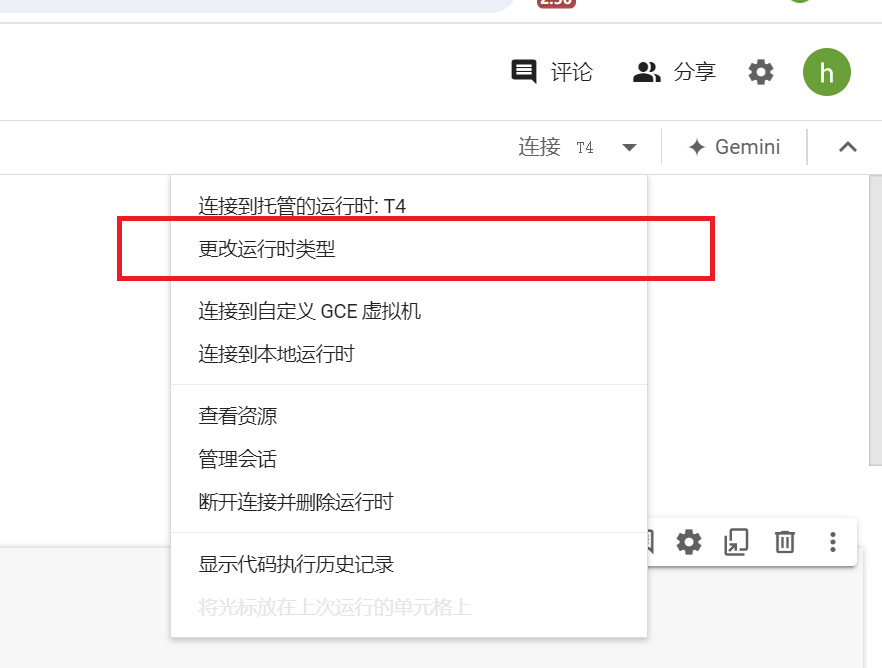
+ 3. 选择GPU运行时
+ 默认是使用CPU运行的,需要我们手动切换成T4 GPU运行。
+  +
+ 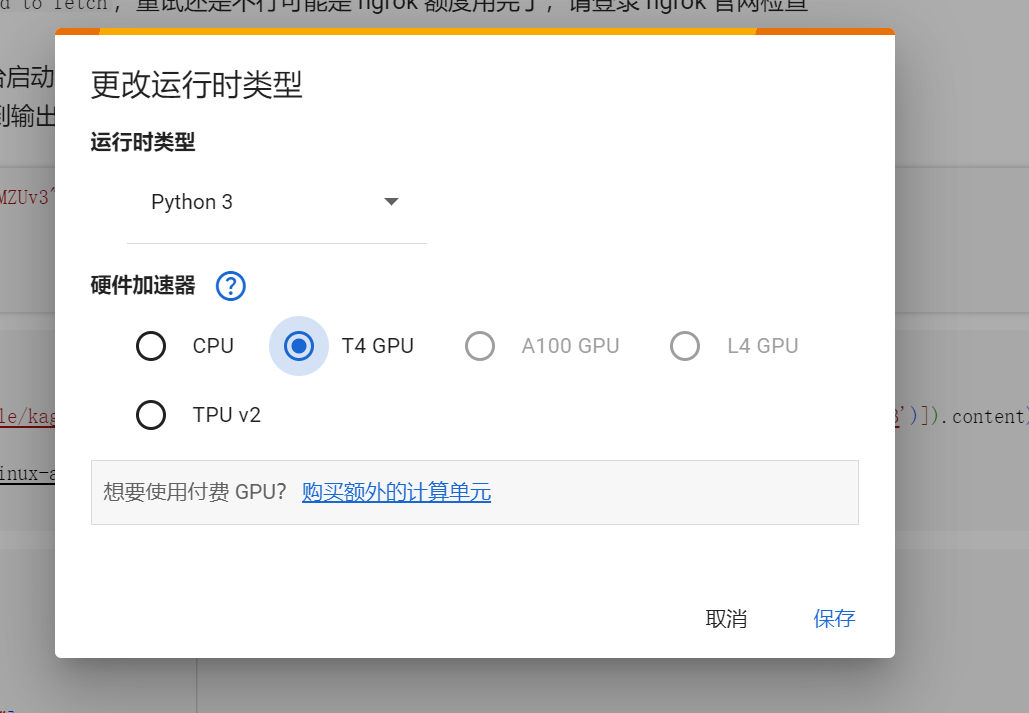 +
+
+
+
+ 4. 设置ngrok密钥和域名,以及使用的模型
+ 将注册的ngrok的NGROK_TOKEN和NGROK_DOMAIN填入脚本中。
+ REPO和MODEL是https://huggingface.co/REPO下的MODEL模型文件名
+  +
+
+
+
+ 5. 运行脚本,稍微等待一分钟左右即可
+ llama.cpp是已经预先编译好的,省去了编译的时间,因此主要是下载模型需要花费一点时间。
+  +
+
+
+
diff --git a/docs/zh/sidebar.md b/docs/zh/sidebar.md
index 1b3b568d..9e724e12 100644
--- a/docs/zh/sidebar.md
+++ b/docs/zh/sidebar.md
@@ -21,6 +21,7 @@
- [翻译源设置](/zh/guochandamoxing.redirect)
- [如何使用大模型API翻译](/zh/guochandamoxing.md)
- [如何使用大模型离线翻译](/zh/offlinellm.md)
+ - [如何部署SakuraLLM到Kaggle/Google Colab](/zh/sakurallmkagglecolab.md)
- [如何使用调试浏览器翻译](/zh/tiaoshiliulanqi.md)
- [文本处理&翻译优化](/zh/textprocess.redirect)
- [各种文本处理方法的作用和用法](/zh/textprocess.md)