mirror of
https://github.com/HIllya51/LunaTranslator.git
synced 2024-12-29 16:44:13 +08:00
62 lines
3.1 KiB
Markdown
62 lines
3.1 KiB
Markdown
## 语音合成根据不同的人物使用不同的声音
|
||
|
||
首先,如果当前文本没有人名之类的东西,那么可以在文本选择器中,额外选择人名的文本。显示的文本将按照选择的先后顺序进行排列。
|
||
|
||
然后,在游戏设置->`语音`(或者设置界面的`语音设置`,但这样将是全局的设置,不建议进行全局设置)中,取消`跟随默认`,然后激活`语音指定`,在其设置中添加一行,将`条件`设置为`包含`,`目标`中填入人名,然后在`指定为`中选择语音。
|
||
|
||
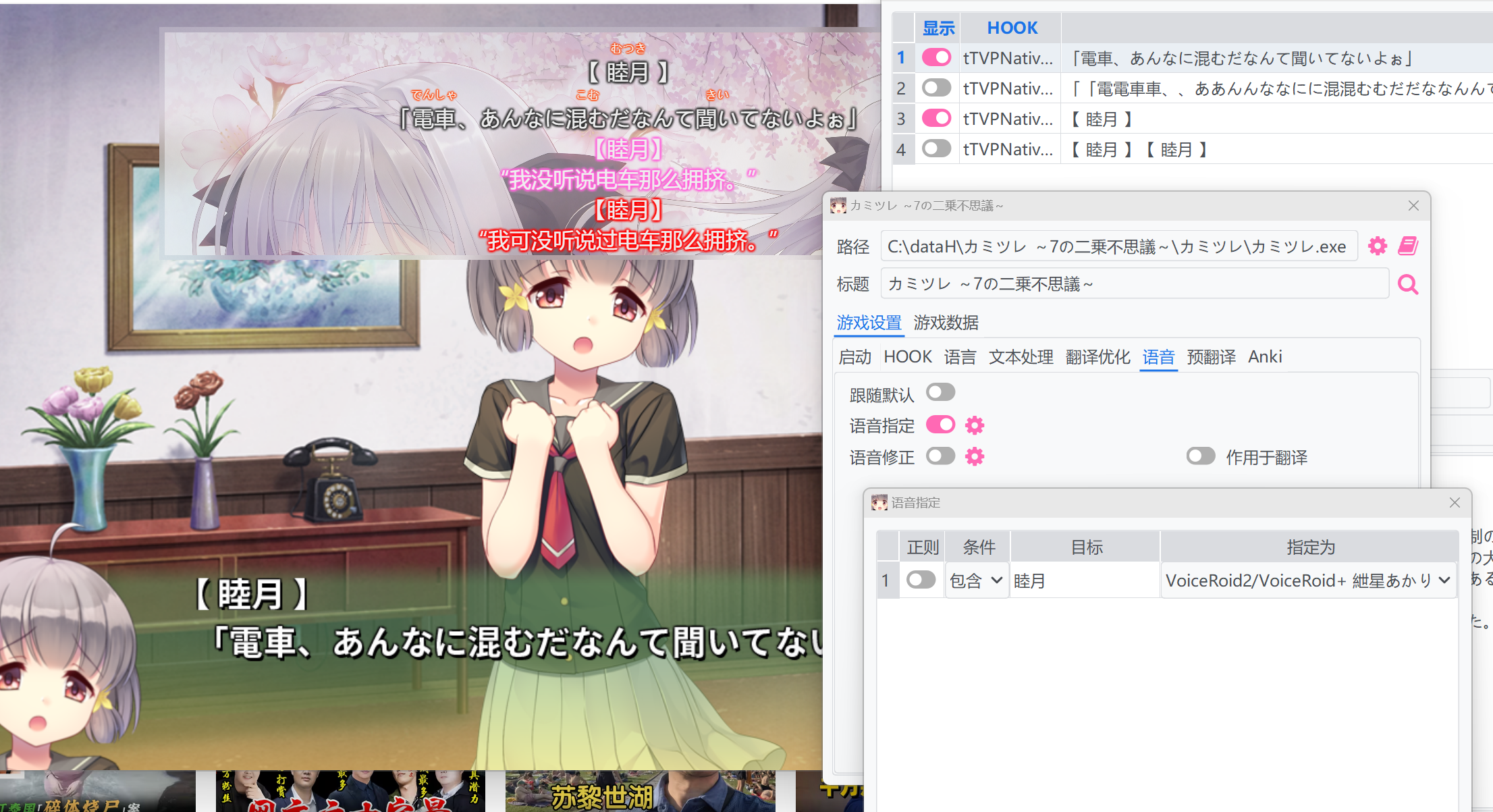
|
||
|
||
但是,由于额外选择了人名文本,使得显示和翻译的内容多出了人名的内容,且语音也会把人名读出来。为了解决这个问题,我们激活`语音修正`,在其中利用正则表达式,将人名及其符号过滤掉。
|
||
如果还激活了`作用于翻译`,则该语音修正也会在显示和翻译的内容中也把人名去掉,从而使得显示的内容和未选取人名条目时一样。
|
||
|
||
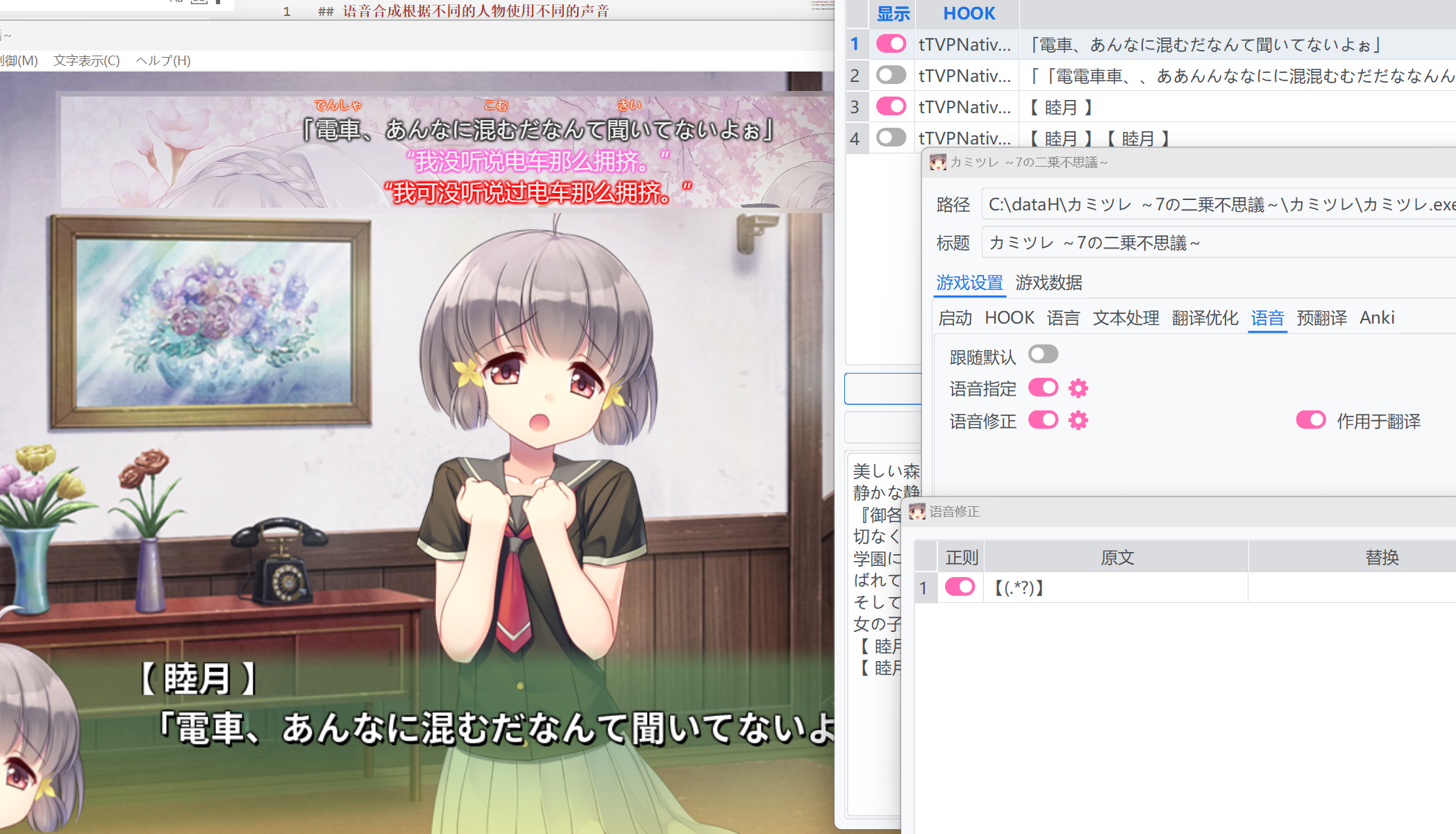
|
||
|
||
|
||
## 语音指定的具体解释
|
||
|
||
当当前文本符合条件时,则执行`指定为`中所指定的动作
|
||
|
||
#### 条件
|
||
|
||
1. 正则
|
||
判断时,是否使用正则表达时进行判断。
|
||
1. 条件
|
||
**首尾** 当为首尾时,仅当目标处于文本的首尾位置时,才符合判定
|
||
**包含** 只要目标出现在文本中,就符合判断。这个是更宽松的判定。
|
||
当同时激活`正则`时,会自动处理正则表达式以兼容该选项。
|
||
1. 目标
|
||
用于判定的文本,通常为**人名**。
|
||
当激活`正则`时,其中的内容将作为正则表达式来实现更准确的判定。
|
||
|
||
#### 指定为
|
||
|
||
1. 跳过
|
||
当判定为符合条件时,跳过对当前文本的朗读
|
||
|
||
1. 默认
|
||
对符合条件的内容,使用默认语音进行朗读。通常,当使用了一个非常宽松的判定时,容易误伤。将设置为该动作的判定移动到更宽松的判定以前,可以避免误伤
|
||
1. 选择语音
|
||
选择后将弹出一个窗口,选择语音引擎和语音。符合条件时将使用该语音进行朗读。
|
||
|
||
## 语音修正的一些问题
|
||
|
||
整个流程是:
|
||
|
||
1. 提取文本
|
||
1. 文本处理-文本预处理
|
||
1. 语音指定
|
||
1. 语音修正
|
||
1. -> 执行语音合成
|
||
1. 显示原文(不激活收到翻译才刷新)
|
||
1. 翻译优化-前处理
|
||
1. 翻译
|
||
1. 翻译优化-后处理
|
||
1. 显示翻译
|
||
|
||
若想要根据人名朗读,且不希望在原文和翻译中显示人名,则必须必须在显示原文前和执行语音合成之前,插入一个动作。
|
||
|
||
由于考虑到大部分情况下,修正的目标和语音修正的目标一致,因此,引入`作用于翻译`选项,使得传递给翻译的文本和语音修正后的朗读文本一致。
|
||
|
||
当然,若使用大模型进行翻译,在原文中保留人名也不失为一个不错的决定,因此这个选项是默认不激活的。
|
||
|
||
当然,若不想在翻译中保留人名,其实也可以考虑在`翻译优化`中将人名过滤掉,但这样显示的原文中仍然会有原文,我不喜欢这样。 |