mirror of
https://github.com/HIllya51/LunaTranslator.git
synced 2024-12-29 00:24:13 +08:00
5.1 KiB
5.1 KiB
部署SakuraLLM到在线GPU平台
1. 设置内网穿透,以将请求转发给llama.cpp服务
注册ngrok,分别获取NGROK_TOKEN和NGROK_DOMAIN,以供后面使用。
对于Google Colab,也可以不注册ngrok,将NGROK_TOKEN置为空,则会使用gradio-tunneling的随机域名进行内网穿透。
若使用ngrok,并填写了NGROK_DOMAIN,则每次运行时将会使用固定的域名进行内网穿透,否则将会使用随机的域名。
启动后,将会在log中看到本次运行的url接口地址,将url接口地址填写到翻译器中即可
全空,使用gradio-tunneling,随机的域名

填写NGROK_TOKEN,使用ngrok,随机的域名

填写NGROK_TOKEN+NGROK_DOMAIN,使用ngrok,固定的域名

2. 部署到在线GPU平台
飞桨Ai Studio
- 免费额度为每日登录领取4小时,并且可以通过一些积分任务获取更多时长

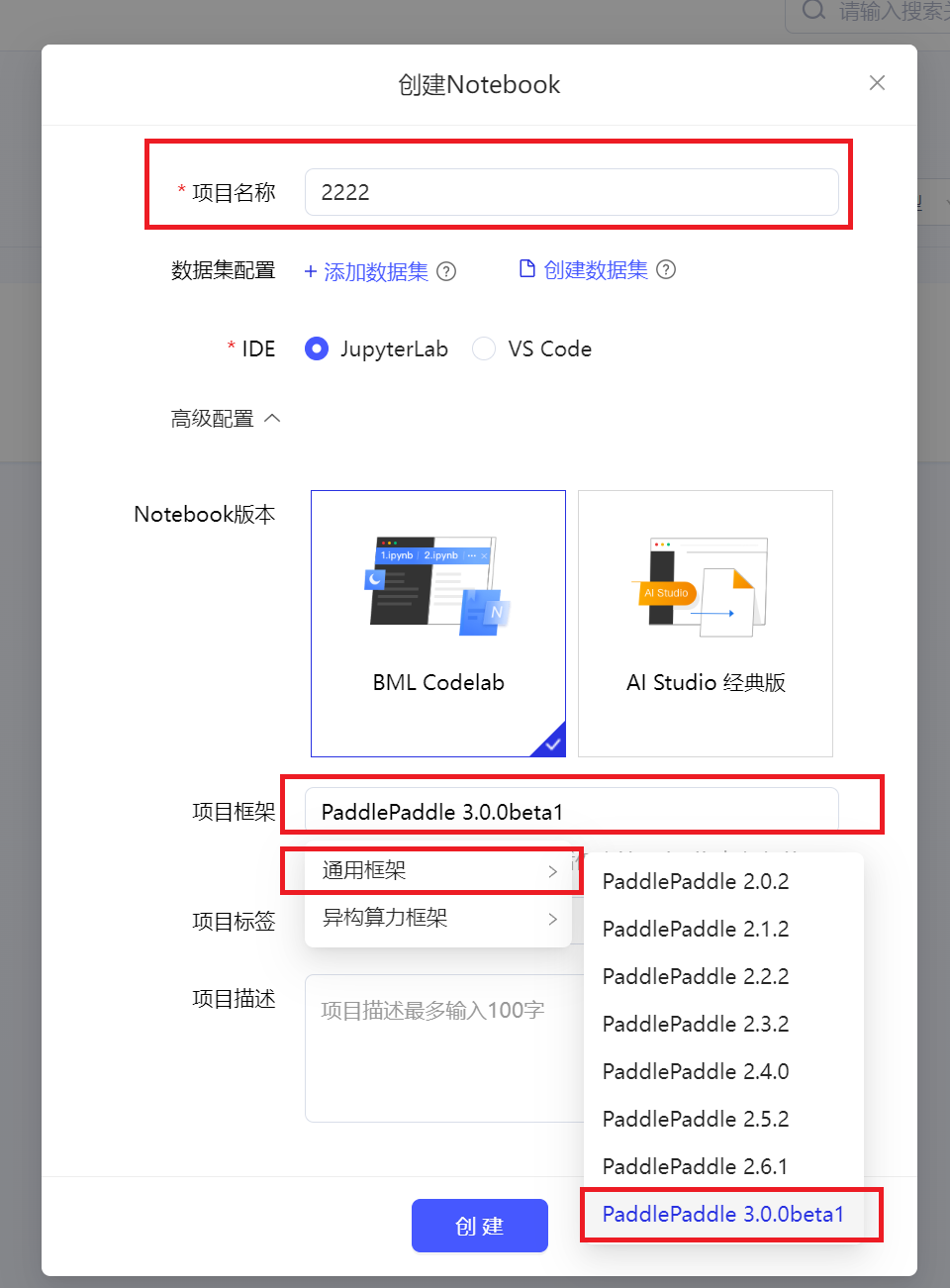
2. 点击启动环境,并选择V100 16GB。启动完毕后,进入环境

3. 下载ipynb脚本,拖拽到文件区中以上传脚本,双击打开脚本。

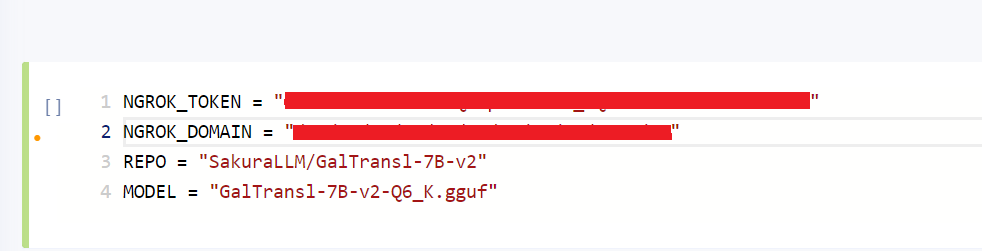
4. 设置ngrok密钥和域名,以及使用的模型
将注册的ngrok的NGROK_TOKEN和NGROK_DOMAIN填入脚本中。 REPO和MODEL是https://huggingface.co/REPO下的MODEL模型文件名
5. 运行脚本,等待模型下载,并获取内网穿透地址
内网穿透地址在下面的log中可以看到。飞桨下载模型速度只有20MB/s,大概需要等待5分钟。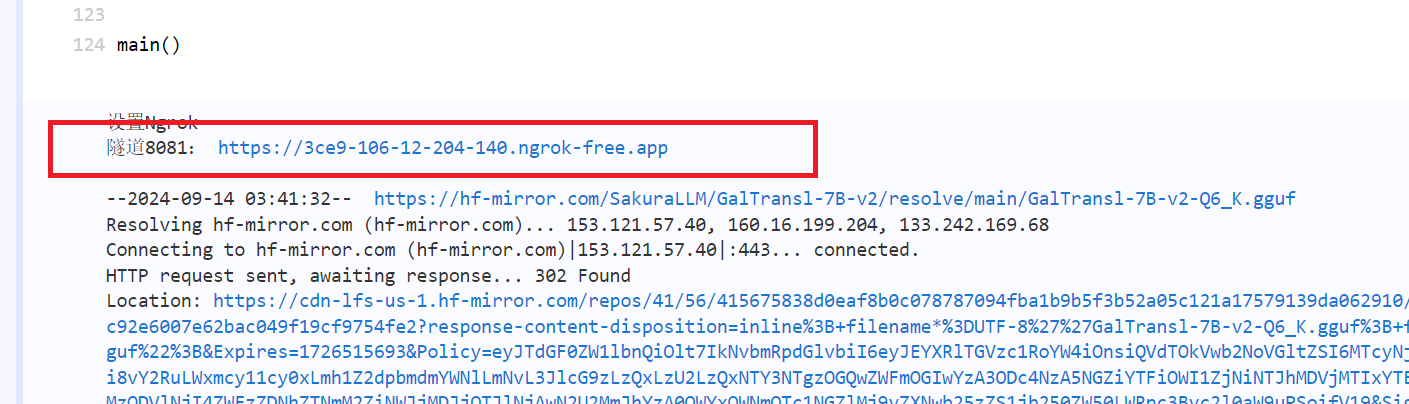
6. 运行结束后,回到项目详情中,主动停止项目,以避免消耗积分。
再次启动环境时会保持之前的文件,直接从5继续开始即可,并且不需要再次下载模型。
Google Colab
- 免费时长约为每天四小时,具体时长根据账号历史用量波动
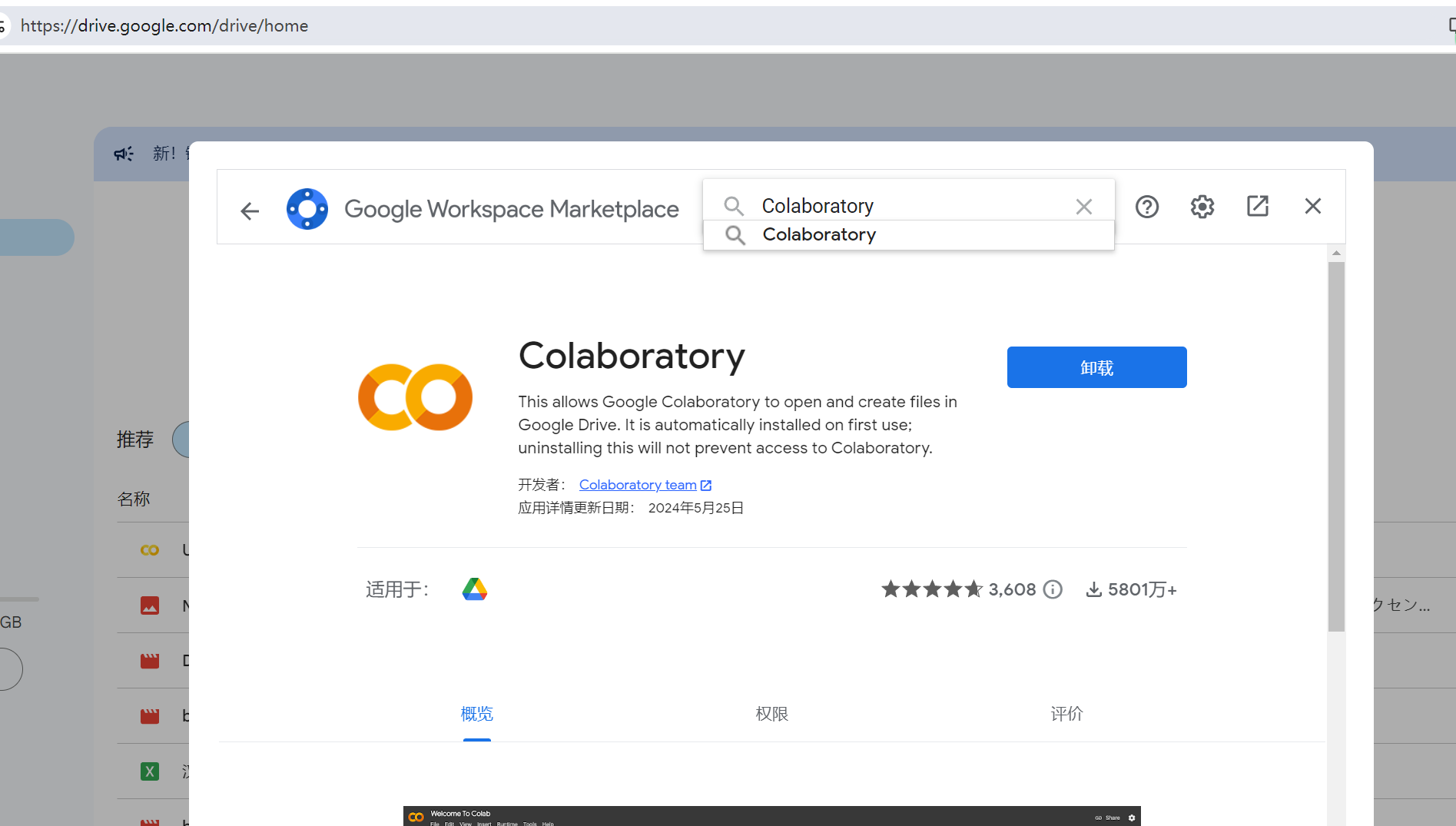
1. 在Google drive中安装Colaboratory应用
点击新建->更多->关联更多应用 在应用市场中搜索Colaboratory安装即可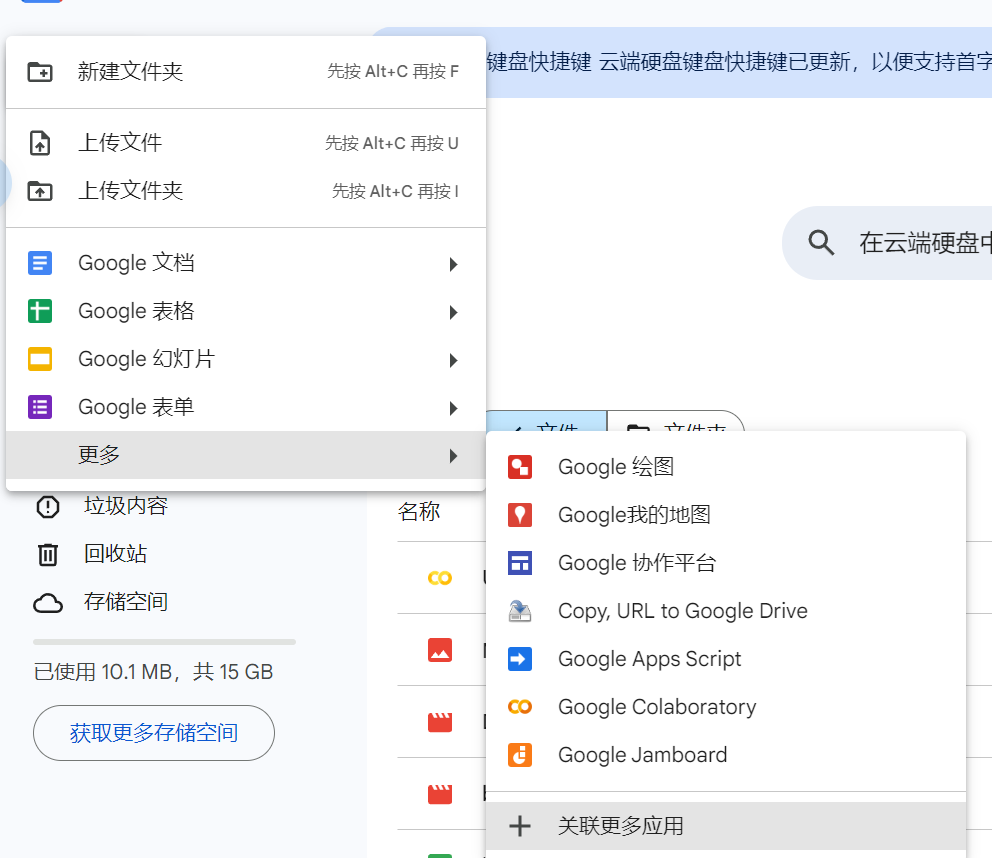
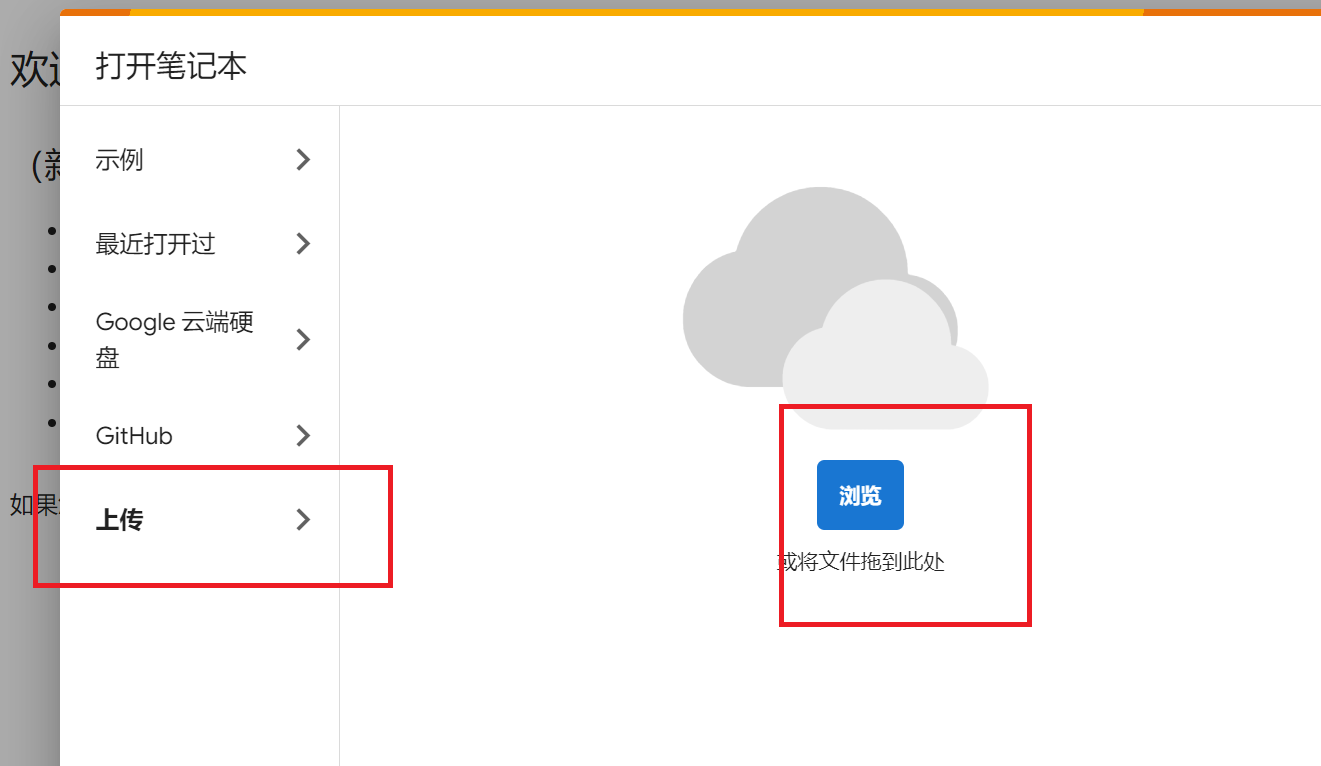
3. 选择GPU运行时
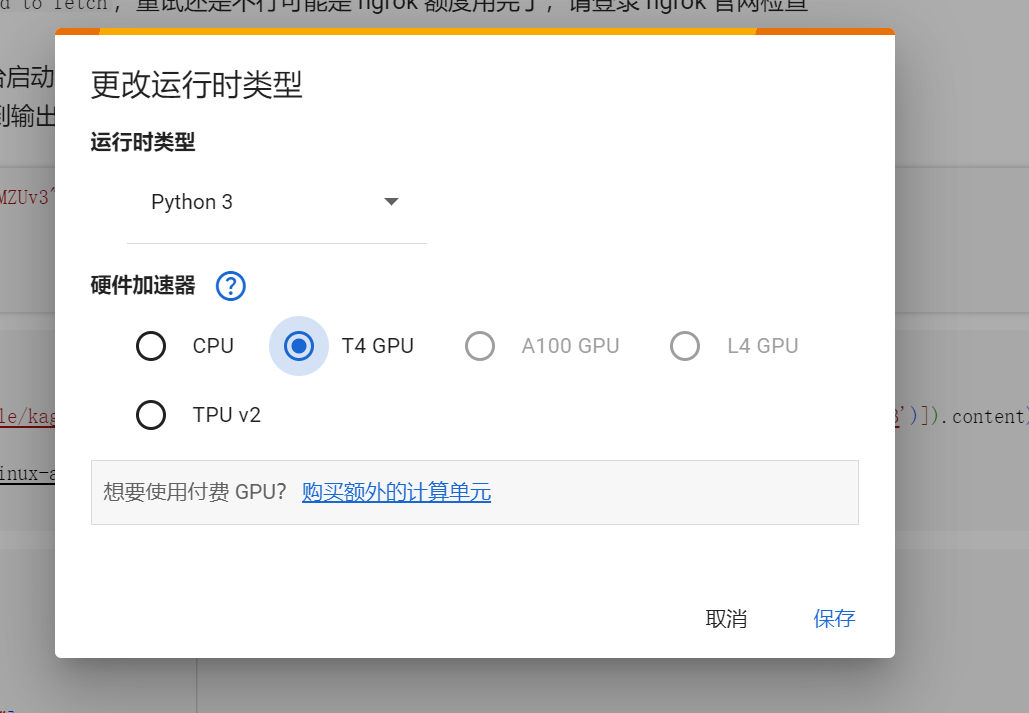
默认是使用CPU运行的,需要我们手动切换成T4 GPU运行。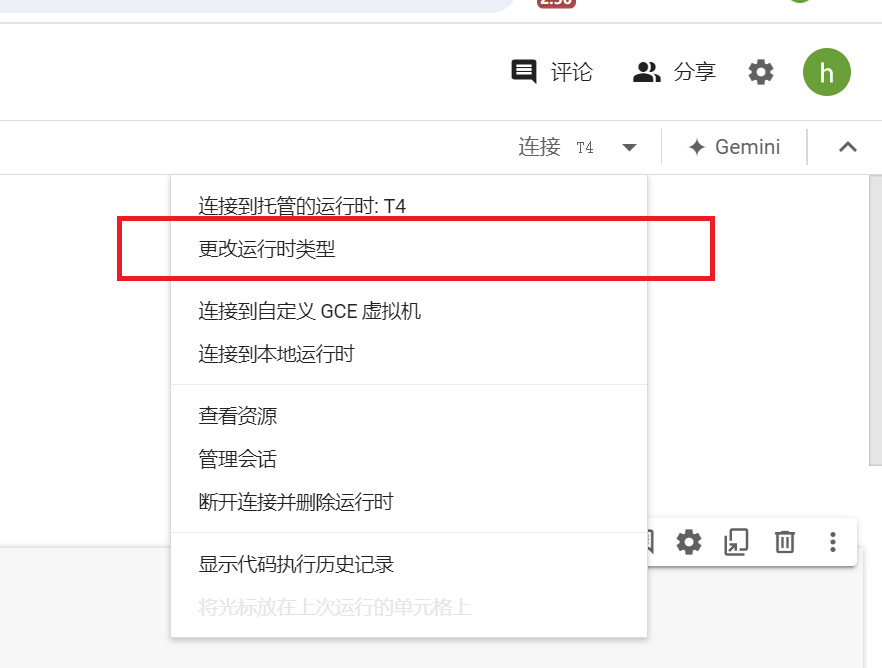
4. 设置ngrok密钥和域名,以及使用的模型
将注册的ngrok的NGROK_TOKEN和NGROK_DOMAIN填入脚本中。 REPO和MODEL是https://huggingface.co/REPO下的MODEL模型文件名

5. 运行脚本,稍微等待一分钟左右即可
llama.cpp是已经预先编译好的,省去了编译的时间,因此主要是下载模型需要花费一点时间。