4.5 KiB
キャラクターごとに異なる声を使用した音声合成
まず、現在のテキストに名前やその他の識別情報が含まれていない<EFBFBD><EFBFBD>合、テキストセレクタで名前のテキストを追加で選択できます。表示されるテキストは選択の順序で並べられます。
次に、ゲーム設定 -> 音声(または設定インターフェースの音声設定、ただしこれはグローバル設定であり、グローバル設定には推奨されません)でデフォルトに従うを無効にし、音声割り当てを有効にして、その設定で行を追加します。条件を含むに設定し、ターゲットにキャラクターの名前を入力し、割り当て先で声を選択します。
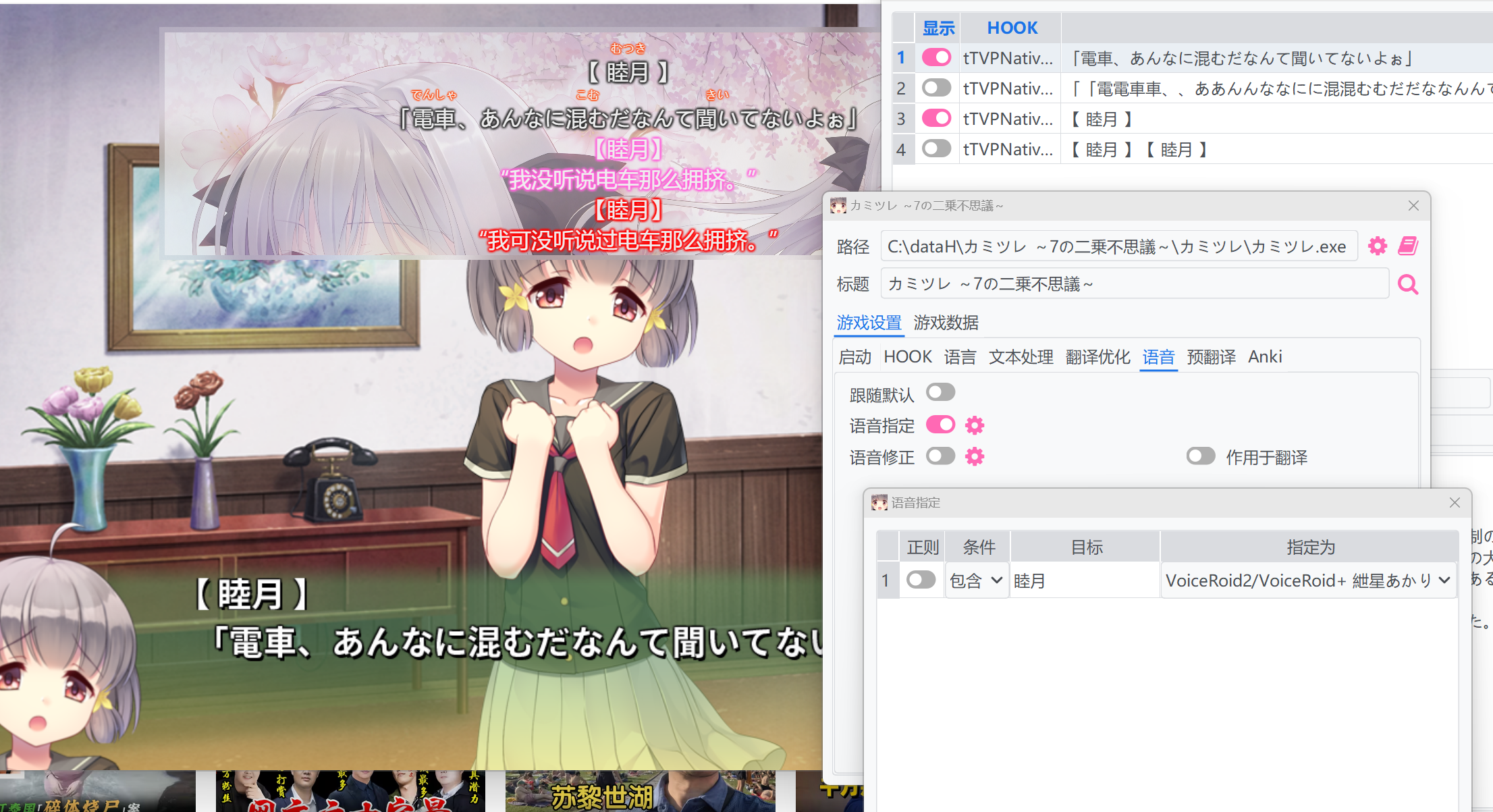
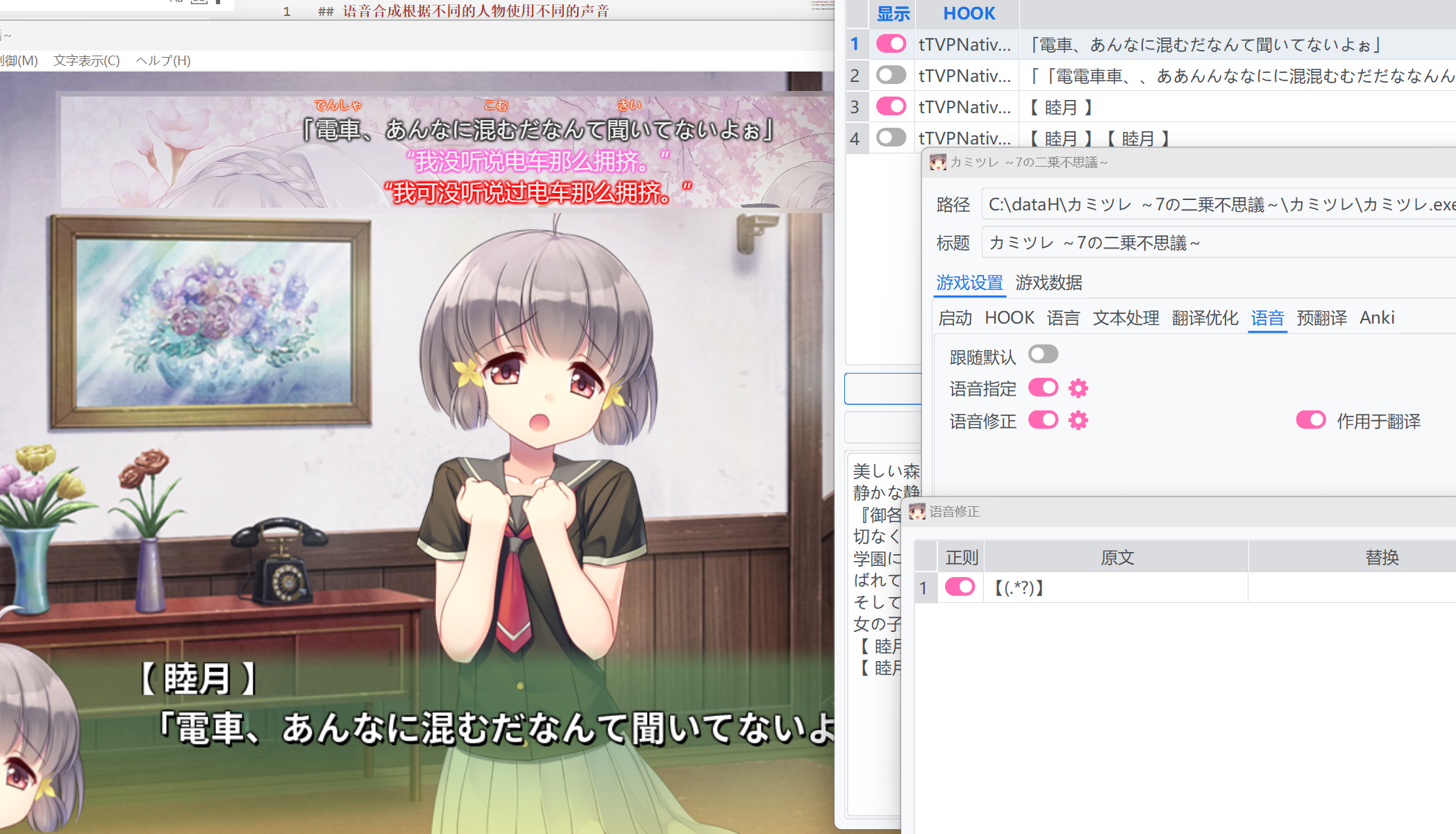
ただし、名前のテキストが追加で選択されているため、表示および翻訳される内容には名前が含まれ、声も名前を読み上げます。この問題を解決するために、音声修正を有効にし、正規表現を使用して名前とその記号をフィルタリングできます。
翻訳に適用も有効にすると、この音声修正は表示および翻訳される内容からも名前を削除し、名前エントリが選択されていない場合と同じように表示されます。
音声割り当ての詳細な説明
現在のテキストが条件を満たすと、割り当て先で指定されたアクションが実行されます。
条件
- 正規表現 判断に正規表現を使用するかどうか。
- 条件
開始/終了 開始/終了に設定すると、ターゲットがテキストの開<E381AE><E9968B><EFBFBD>または終了にある場合にのみ条件が満たされます。
含む ターゲットがテキストに現れる限り、条件が満たされます。これはより緩やかな判断です。
正規表現が同時に有効になっている場合、正規表現はこのオプションに対応するように自動的に処理されます。 - ターゲット
判断に使用されるテキスト、通常はキャラクターの名前。
正規表現が有効になっている場合、内容はより正確な判断のために正規表現として使用されます。
割り当て先
-
スキップ 条件が満たされると、現在のテキストの読み上げをスキップします。
-
デフォルト 条件を満たす内容に対してデフォルトの声を使用します。通常、非常に緩やかな判断を使用する場合、誤検出が発生しやすいです。このアクションに設定された判断をより緩やかな判断の前に移動することで、誤検出を回避できます。
-
声を選択 選択後、声のエンジンと声を選択するウィンドウが表示されます。条件が満たされると、この声が読み上げに使用されます。
音声修正のいくつかの問題
全体のプロセスは次のとおりです:
- テキストを抽出
- テキスト処理 - 前処理
- 音声割り当て
- 音声修正
- -> 音声合成を実行
- 元のテキストを表示(翻訳を受信してもリフレッシュされない)
- 翻訳最適化 - 前処理
- 翻訳
- 翻訳最適化 - 後処理
- 翻訳を表示
キャラクターの名前に従って読み上げたい場合、元のテキストと翻訳に名前が表示されないようにするには、元のテキストを表示し、音声合成を実行する前にアクションを挿入する必要があります。
ほとんどの場合、修正対象と音声修正対象が同じであると考えられるため、翻訳に適用オプションが導入され、翻訳に渡されるテキストが修正された読み上げテキストと一致するようになります。
もちろん、大規模モデルを使用して翻訳する場合、元のテキストにキャラクターの名前を保持することも良い決定ですので、このオプションはデフォルトで有効になっていません。
もちろん、翻訳にキャラクターの名前を保持したくない場合は、翻訳最適化で名前をフィルタリングすることも考えられますが、この方法では元のテキストに名前が含まれたままになるため、私は好きではありません。